CODEX
Azure Cosmos DB. Partitioning.
This article is a part of the series. Check others for more details around Cosmos DB:
- Azure Cosmos DB. Introduction.
- Azure Cosmos DB. Partitioning.
- Azure Cosmos DB. Partitioning. Hands-on analysis.
- Azure Cosmos DB. The power of Logs.
- Azure Cosmos DB. Logs. Beware of the Costs
What is a partition key and why is it important?
Cosmos DB is designed to scale horizontally based on the distribution of data between physical partitions (PP). Think of it as separately deployable self-sufficient nodes which are synchronized and coordinated by a central gateway.
The second essential part of the architecture is the logical partition (LP) — it’s bucket of documents which share the same characteristic (partition key) and are supposed to be stored fully in the same physical partition.

There are two major limitations within Physical Partitions:
- Max throughput: 10k RUs
- Max data size (sum of all LPs): 50GB
Logical partition has one — 20GB limit in size.
NOTE: Size limits have grown since initial releases of Cosmos DB and I won’t be surprised if they will increase even further.
How to select the right partition key for my container?
It is critical to analyze the application data “consumption” pattern when considering the right partition key. Is it balanced and linear? Seasonal? Linked to daytime activity or driven by a specific region? etc..
Based on the Microsoft recommendation for maintainable data growth you should select the most granular partition key (like Id of the document or a composite field). The main reason being:
Spread request unit (RU) consumption and data storage evenly across all logical partitions. This ensures even RU consumption and storage distribution across your physical partitions.
In a very rare scenario larger partitions might work, although at the same time such solutions should implement data archiving to maintain DB size from the get-go (see example below explaining why). Without proper data governance and clean-up you should be ready to accept increasing operational costs just to maintain the same performance.
On top of that you should be ready solving “hot” partitions, PP data skew, unexpected “splits” and rather unpredictable performance from your DB.
Having a granular partitioning strategy on the other hand will lead to an RU overhead which is caused by query fan-out between number of physical partitions (PPs).
Worth mentioning that larger number of partitions will generate a higher overhead since without usage of a partition key in the query system doesn’t know “address” of PP where to look for it and will spin up requests to all PPs to scan index and in worst case go through each document. But with careful indexing it will be negligible comparing to issues occurring when data starts to grow beyond 50-, 100-, 150GB.
Some recommend aiming for high “cardinality” when designing partitioning strategy. from wiki:
cardinality of a set is a measure of the “number of elements” of the set. For example, the set A={2,4,6} contains 3 elements, and therefore A has cardinality of 3
Important to note that high cardinality here should be a target measure of number of partition keys in your container rather than documents per partition key.
Why large partitions are a terrible choice in most cases?
…even though documentation says “select whatever works best for you”
Cosmos DB is designed to scale horizontally and provisioned throughput per PP is limited to the [total provisioned per container (or DB)] / [number of PP].
Once PP split occurs due to exceeding 50GB size your max throughput for existing PPs as well as two newly created PPs will be lower then it was before split.
So imagine following scenario:
- You’ve created container with provisioned 10k RUs and CustomerId as a partition key (which will require one underlying physical partition #1). Maximum throughput per PP is 10k/1 = 10k RUs.
- Application is growing and 3 large clients with C1[10GB], C2[20GB] and C3[10GB] of invoices were onboarded to the system. Data of C1, C2, and C3 can be operated with up to 10k request units per second.
- When C4 client loaded [15GB] of invoices into the system Cosmos DB breached 50GB partition size limit and will have to split PP#1 into two newly created partition PP#2 (30GB) and PP#3 (25GB). Maximum throughput per PP is 10k/2 = 5k RUs.
- C1, C2, C3 and C4 -data can be operated with up to 5k RUs
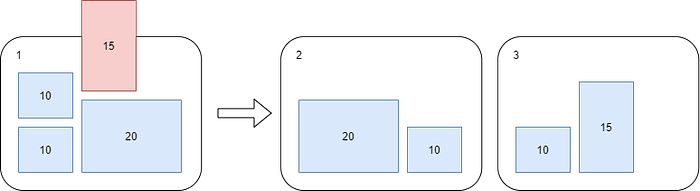
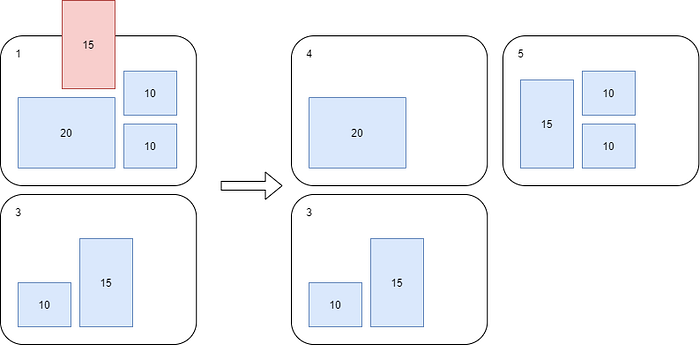
- Two more customers C5[10GB] C6[15GB] were added to the system and both ended-up in PP2 which lead to another split -> PP4 (20GB) and PP5 (35GB). Maximum throughput per PP is now 10k/3 = 3.333k RUs.
- C1–6 data can be operated with 3.3k RUs
Why partition key with high cardinality per container is the best choice for growth and maintainability?
..even though some might say you will pay more for your queries.
When assessing high cardinality partition key we have to accept that it comes with a cost of executing cross-partition query. In a nutshell, if your query doesn’t filter by partition key Cosmos DB doesn’t know where to go for the data. Thus, it has to fan-out the request to all physical partitions and validate it against the index of each PP to find the data you are looking for.
You probably remembered all non-indexed queries you’re running in your app, and correct, they will cost much more to execute.
And if someone has doubts, reassuring statement from the official documentation:
Because of the Azure Cosmos DB’s ability to parallelize cross-partition queries, query latency will generally scale well as the system adds physical partitions. However, RU charge will increase significantly as the total number of physical partitions increases.
Why is it better? To understand the benefit of the granular partition key we will have to go back to our example from the previous section but with a slight modification. We will use InvoiceId as a partition key which gives a large number of logical partitions of small size..
- You’ve created container with provisioned 10k RUs and InvoiceId as a partition key (which will require one underlying physical partition #1). Maximum throughput per PP is 10k/1 = 10k RUs.
- Application is growing and 3 large clients with C1[10GB], C2[20GB] and C3[10GB] of invoices were onboarded to the system. Data of C1, C2, and C3 can be operated with up to 10k request units per second.
- When C4 client loaded [15GB] of invoices into the system Cosmos DB breached 50GB partition size limit and will have to split PP#1 into two newly created partition PP#2 (~27.5GB) and PP#3 (~27.5GB). Maximum throughput per PP is 10k/2 = 5k RUs.
- C1, C2, C3 and C4 -data can be operated with up to 10k RUs as data is distributed equally (after split 50% is in PP#2 and 50% — PP#3) hence querying data for C1 can simultaneously use 5k RUs from PP#1 and 5k RUs from PP#2.
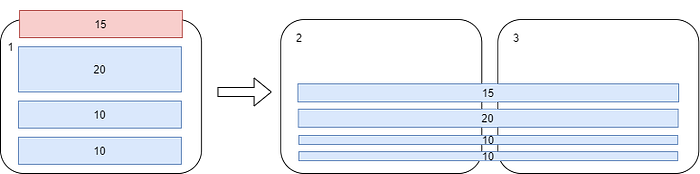
- Two more customers C5[10GB] C6[15GB] were added to the system though existing PPs had sufficient space (90/100 GB) to accommodate data. Maximum throughput per PP is now 10k/2 = 5k RUs.
- C1–6 data can be operated up to 5k RUs
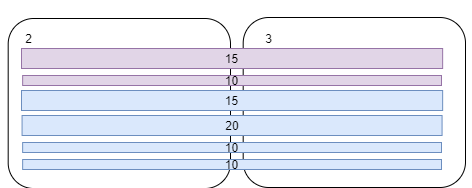
This example highlights that with equal distribution of the logical partitions between physical partitions we can achieve sustainable growth. One of the simplest ways to distribute data in such manner is to go with small and high cardinality logical partition.
Conclusion
There is no one-size-fits-all solution in Cosmos DB and every application will have to tailor the partition key design to its needs and configuration. But if you diligently do the analysis early in the design process Cosmos DB can be an effective tool.
Keep in mind distribution of logical partitions between physical “nodes” as well as indexing and cross-partition query have an impact on application performance.

